Au GTC 2022 ce printemps, NVIDIA s'est d'abord annoncé comme un fabricant de puissants processeurs pour serveurs. Nous parlons de puces Grace et d'assemblages hybrides Grace Hopper, combinant des cœurs Arm v9 et des accélérateurs basés sur l'architecture Hopper, qui devraient commencer à être livrés au premier semestre de l'année prochaine. De nombreux développeurs de supercalculateurs sont déjà intéressés par de nouveaux produits. Avant la conférence Hot Chips 34, la société a révélé un certain nombre de détails sur les puces.
Grace est fabriqué à l'aide de la technologie de processus TSMC 4N - il s'agit d'une variante du N4 spécialement optimisée pour les solutions NVIDIA, qui fait partie de la série de processus 5 nm du fabricant taïwanais. Chaque matrice Grace contient 72 cœurs Arm v9 prenant en charge les extensions vectorielles évolutives SVE2 et les extensions de virtualisation prenant en charge S-EL2. Comme indiqué précédemment, NVIDIA a choisi le noyau Arm Neoverse pour la nouvelle plate-forme.
Le processeur Grace est également conforme à un certain nombre d'autres spécifications Arm, notamment le contrôleur d'interruption générique (GIC) v4.1 conforme à RAS v1.1, l'unité de gestion de la mémoire système (SMMU) v3.1 et le partitionnement et la surveillance de la mémoire (MPAM). Grace a deux cristaux de base, ce qui donne un total de 144 cœurs - un nombre record dans les mondes Arm et x86.
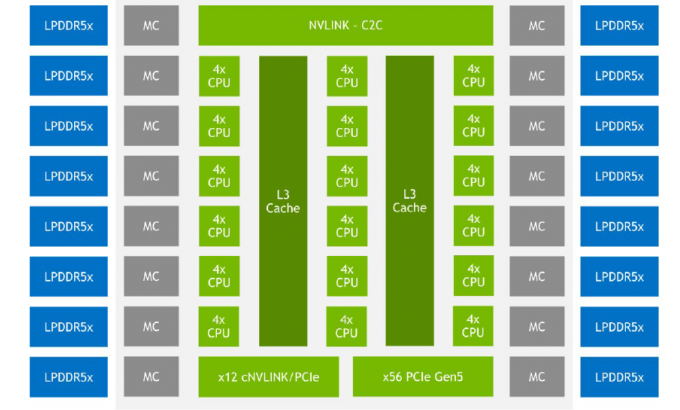
Les unités intérieures Grace sont connectées via le Scalable Coherency Fabric (SCF), la variation de NVIDIA sur le réseau CMN-700 utilisé dans les conceptions Arm Neoverse. La performance de cette interconnexion est de 3,2 To/s. Dans le cas de Grace, il suppose 117 Mo de cache L3 et maintient la cohérence dans quatre sockets (via la nouvelle version de NVLink).
Mais SCF prend en charge la mise à l'échelle. Jusqu'à présent, au niveau matériel, il est limité à deux blocs Grace, et cela représente déjà 144 cœurs et 234 Mo de cache L3. Les cœurs et les partitions de cache (SCC) sont répartis sur l'usine de maillage interne SCF. Les commutateurs (CSN) servent d'interfaces avec les cœurs, les partitions de cache et le reste du système. Les blocs CSN communiquent directement entre eux ainsi qu'avec les contrôleurs LPDDR5X et PCIe 5.0/cNVLink/NVLink C2C.
La puce prend en charge PCI Express 5.0. Au total, le contrôleur prend en charge 68 lignes, dont 12 peuvent également fonctionner en mode cNVLink (NVLink avec cohérence). Une interface x16 peut être divisée en deux interfaces x8. Également sur le diagramme fourni par NVIDIA, vous pouvez voir jusqu'à 16 contrôleurs LPDDR5x à double canal. Bande passante mémoire déclarée au niveau de plus de 1 To/s pour l'assemblage (jusqu'à 546 Go/s par puce CPU).
NVIDIA voit une nouvelle version de NVLink, NVLink-C2C, qui est sept fois plus rapide que PCIe 5.0 et capable de fournir des taux de transfert de données bidirectionnels allant jusqu'à 900 Go/s, tout en étant cinq fois plus économique. La consommation spécifique de la nouveauté est de 1,3 pJ/bit, ce qui est inférieur à celui d'AMD Infinity Fabric avec 1,5 pJ/bit. Cependant, il existe aussi des solutions plus économiques, par exemple UCIe (~0,5 pJ/bit).
NVLink-C2C vous permet d'implémenter un pool de mémoire "plat" unifié avec un espace d'adressage commun pour Grace Hopper. Au sein d'un nœud, il est possible d'accéder librement à la mémoire des voisins. Mais pour combiner plusieurs nœuds, vous aurez besoin d'un commutateur NVSwitch externe. Il aura une hauteur de 1U et fournira 128 ports NVLink 4 avec jusqu'à 6,4 To/s de bande passante agrégée en duplex.
Les performances de Grace promettent également d'atteindre un niveau record grâce à une architecture optimisée et une interconnexion rapide. Même selon les chiffres préliminaires publiés par NVIDIA, nous parlons de 370 points SPECrate2017_int_base pour un seul dé Grace et de 740 points pour un assemblage à double matrice à 144 cœurs - et cela utilise le compilateur GCC habituel sans optimisations subtiles de la plate-forme. Ce dernier chiffre est nettement supérieur aux résultats présentés par le Alibaba T-Head Yitian 710 à 128 cœurs, utilisant également l'architecture Arm v9, et l'AMD EPYC 7773X à 64 cœurs.
2022-08-21 03:51:49
Auteur: Vitalii Babkin