少しずつ、Compute Express Link 標準が市場に出回っています。サポートされているプロセッサはまだありませんが、新しい相互接続のためのインフラストラクチャ要素とそれに基づく概念の多くは、すでに準備が整っています。特に、新しいコントローラです。およびメモリモジュールは定期的にデモンストレーションされます。しかし、標準自体は進化しています。 2019年に仕様が公開されたバージョン1.1では、基礎が築かれただけでした。
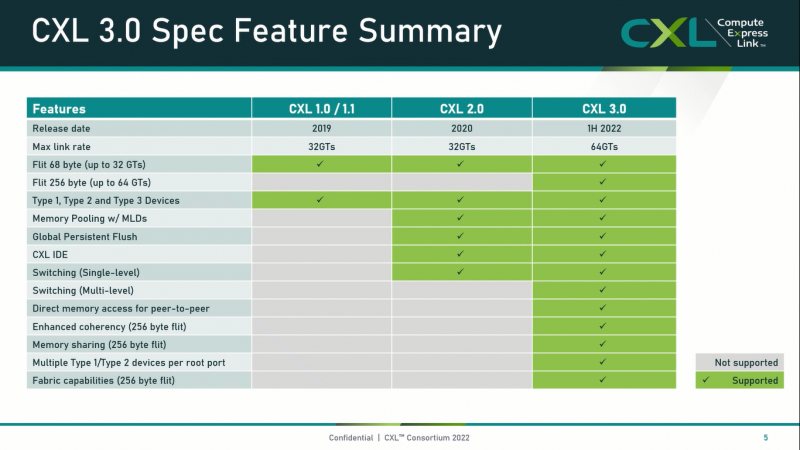
しかし、すでにバージョン 2.0 で、CXL は多くの革新を受けており、新しいバスについてだけでなく、全体のコンセプトとサーバー アーキテクチャへのアプローチの変更について話すことができます。そして現在、標準の開発を担当するコンソーシアムが最新のバージョン 3.0 仕様を公開し、CXL の機能をさらに拡張しています。
拡張するだけでなく、バージョン 3.0 では、遅延を増やすことなく、新しい規格が 64 GT / s のサポートを受けました。 PCIe 6.0 規格に基づいているため、これは驚くべきことではありません。しかし、開発者の主な努力は、リソースの分解と構成可能なインフラストラクチャの作成のアイデアのさらなる開発に集中していました。
CXL 3.0 ファブリック自体により、マルチヘッド デバイスの作成と接続、ファクトリ管理機能の拡張、メモリ プールのサポートの改善、高度なコヒーレンス モード、およびマルチレベル スイッチングのサポートが可能になりました。同時に、CXL 3.0 は以前のすべてのバージョン (2.0、1.1、さらには 1.0) との下位互換性を保持しています。この場合、使用可能な機能の一部がアクティブ化されません。
重要な技術革新の 1 つは、マルチレベル スイッチングです。現在、CXL 3.0 ファブリックのトポロジーは、スイッチのグループが上位レベルのスイッチに接続されている、線形からカスケードまで、ほぼすべてのものにすることができます。同時に、プロセッサの各ルート ポートは、任意の組み合わせのスイッチを介して、さまざまなタイプのデバイスの同時接続をサポートします。
もう 1 つの興味深い革新は、ピア ツー ピア (P2P) ダイレクト メモリ アクセスのサポートでした。簡単に言えば、隣接するラックなどに配置された複数のアクセラレータは、ホスト プロセッサに影響を与えることなく、相互に直接通信できます。いずれの場合も、アクセス保護と通信セキュリティが保証されます。さらに、各デバイスのメモリを 16 の独立したセグメントに分割することが可能です。
同時に、グループの階層構造がサポートされ、その中でメモリとキャッシュの内容の一貫性が保証されます (無効化が提供されます)。現在、プールからのメモリへの排他的アクセスに加えて、コヒーレンスのためのハードウェア サポートにより、複数のホストによる 1 つのメモリ ブロックへの共有アクセスも同時に利用できます。プーリングはもはやサードパーティのソフトウェアに任されていませんが、標準化された工場管理者によって実行されます。
新機能の組み合わせにより、メモリとコンピューティング リソースを分離するという考え方が新しいレベルに引き上げられます。CXL 3.0 ファブリック (グローバル ファブリック アタッチド メモリ、GFAM) に接続された単一のメモリ プールが実際に存在するシステムを構築できるようになりました。計算モジュールとは別に。同時に、最大 4096 の接続ポイントに対応する能力は、工場の物理的な限界に突き当たります。
プールには、さまざまなタイプのメモリ (DRAM、NAND、SCM) を含めることができ、直接または CXL スイッチを介してコンピューティング パワーに接続できます。デバイス自体によって、デバイスのタイプ、機能、およびその他の特性について報告するためのメカニズムが提供されます。このようなアーキテクチャは、次世代ニューラル ネットワークのデータ セットがすでに非常に巨大なサイズに達している機械学習の世界で需要があることが約束されています。
CXL グループには現在、Intel、Arm、AMD、IBM、NVIDIA、Huawei、Microsoft、Alibaba Group、Google、Meta などの主要なクラウド プロバイダー、HPE やデル EMC.
2022-08-02 13:13:46
著者: Vitalii Babkin