Untether AI ha annunciato l'architettura AI di prossima generazione speedAI (nome in codice "Boqueria"), incentrata sui carichi di inferenza. Con un'efficienza energetica di 30 Tflops/W e prestazioni fino a 2 Pflops per chip, speedAI stabilisce un nuovo standard per l'efficienza energetica e la densità di calcolo, afferma l'azienda.
Poiché il calcolo in memoria è molto più efficiente dal punto di vista energetico rispetto alle architetture tradizionali in alcune attività, può fornire prestazioni più elevate a parità di energia. La prima generazione di dispositivi runAI nel 2020, Untether AI raggiunge un'efficienza energetica di 8 Tflops/W per l'elaborazione INT8. La nuova architettura speedAI fornisce già 30 TFlops/W.
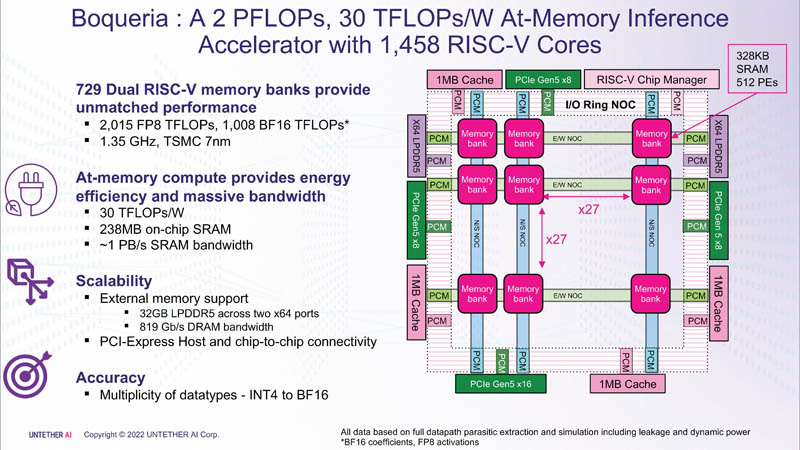
Ciò è stato ottenuto grazie all'architettura di seconda generazione, all'uso di oltre 1400 core RISC-V a 7 nm ottimizzati (1,35 GHz) con istruzioni personalizzate, al controllo del flusso di dati ad alta efficienza energetica e all'introduzione del supporto FP8. Insieme, questo ha permesso di quadruplicare l'efficienza di speedAI rispetto a runAI. La novità può essere adattata in modo flessibile a varie architetture di reti neurali. Concettualmente, speedAI assomiglia a un altro chip RISC-V da mille core: Esperanto ET-SoC-1.
Il primo membro della famiglia speedAI, speedAI240, fornisce 2 Pflop per i calcoli FP8 o 1 Pflop per le operazioni BF16. Ciò si traduce in un'efficienza leader del settore, come la dichiarazione di prestazioni di BERT di 750 richieste al secondo per watt (qps/w), che secondo l'azienda è 15 volte più veloce delle GPU odierne. È stato possibile ottenere un aumento delle prestazioni grazie alla stretta integrazione di elementi di calcolo e memoria.
Per ogni blocco SRAM da 328 KB, ci sono 512 unità di calcolo che supportano i formati INT4, INT8, FP8 e BF16. Ogni unità di calcolo ha due core RISC-V personalizzati a 32 bit (RV32EMC) con supporto per quattro thread e 64 SIMD. Ci sono 729 blocchi in totale, quindi in totale il chip trasporta 238 MB di SRAM e 1458 core. I blocchi sono collegati tra loro da una rete mesh, a cui è collegato anche un bus IO ad anello, che trasporta quattro blocchi di cache condivisa da 1 MB, due controller LPDRR5 (64 bit) e porte PCIe 5.0: una x16 per la connessione all'host e tre x8 per combinare le fiches.
Il throughput totale della SRAM è di circa 1 PB/s, le reti mesh vanno da 1,5 a 1,9 TB/s, i bus IO sono 141 GB/s in entrambe le direzioni e 32 GB DRAM sono poco più di 100 GB/s. Le interfacce PCIe consentono di combinare fino a tre acceleratori, con sei chip speedAI240 ciascuno. Le soluzioni speedAI saranno offerte sia sotto forma di chip singoli sia come parte di schede PCIe già pronte e moduli M.2. Le prime consegne a clienti selezionati dovrebbero iniziare nella prima metà del 2023.
2022-08-25 04:02:28
Autore: Vitalii Babkin