Untether AI는 추론 부하에 중점을 둔 차세대 AI 아키텍처 speedAI(코드명 "Boqueria")를 발표했습니다. 30Tflops/W의 에너지 효율성과 칩당 최대 2Pflops의 성능을 갖춘 speedAI는 전력 효율성과 컴퓨팅 밀도에 대한 새로운 표준을 제시합니다.
앳 메모리 컴퓨팅은 일부 작업에서 기존 아키텍처보다 훨씬 더 에너지 효율적이기 때문에 동일한 양의 에너지에 대해 더 높은 성능을 제공할 수 있습니다. 2020년 runAI 장치의 1세대인 Untether AI는 INT8 컴퓨팅을 위해 8Tflops/W의 에너지 효율성을 달성합니다. 새로운 speedAI 아키텍처는 이미 30TFlops/W를 제공합니다.
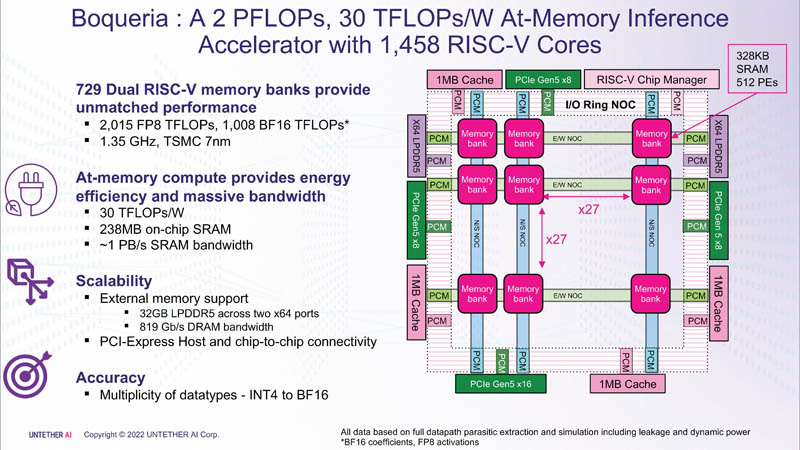
이는 2세대 아키텍처, 맞춤형 명령과 함께 1400개 이상의 최적화된 7nm RISC-V 코어(1.35GHz) 사용, 에너지 효율적인 데이터 흐름 제어 및 FP8 지원 도입 덕분에 달성되었습니다. 이를 통해 runAI에 비해 speedAI의 효율성을 4배 높일 수 있었습니다. 이 참신함은 신경망의 다양한 아키텍처에 유연하게 적용될 수 있습니다. 개념적으로 speedAI는 또 다른 천 코어 RISC-V 칩인 Esperanto ET-SoC-1과 유사합니다.
speedAI 제품군의 첫 번째 구성원인 speedAI240은 FP8 계산을 위한 2Pflops 또는 BF16 연산을 위한 1Pflops를 제공합니다. 그 결과 BERT의 성능 주장 와트당 초당 750개 요청(qps/w)과 같은 업계 최고의 효율성을 얻을 수 있습니다. 이 성능은 오늘날 GPU보다 15배 더 빠릅니다. 컴퓨팅 요소와 메모리의 긴밀한 통합으로 인해 성능 향상을 달성할 수 있었습니다.
각 328KB SRAM 블록에는 INT4, INT8, FP8 및 BF16 형식을 지원하는 512개의 컴퓨팅 장치가 있습니다. 각 컴퓨팅 장치에는 4개의 스레드와 64개의 SIMD를 지원하는 2개의 32비트(RV32EMC) 맞춤형 RISC-V 코어가 있습니다. 총 729개의 블록이 있으므로 이 칩에는 총 238MB의 SRAM과 1458개의 코어가 있습니다. 블록은 4개의 1MB 공유 캐시 블록, 2개의 LPDRR5 컨트롤러(64비트) 및 PCIe 5.0 포트(호스트 연결용 x16 1개)를 운반하는 링 IO 버스도 연결된 메시 네트워크에 의해 서로 연결됩니다. 그리고 칩 결합을 위한 3개의 x8.
SRAM의 총 처리량은 약 1PB/s, 메시 네트워크는 1.5~1.9TB/s, IO 버스는 양방향으로 141GB/s, 32GB DRAM은 100GB/s를 약간 넘습니다. PCIe 인터페이스를 사용하면 각각 6개의 speedAI240 칩과 함께 최대 3개의 가속기를 결합할 수 있습니다. speedAI 솔루션은 개별 칩 형태와 기성 PCIe 카드 및 M.2 모듈의 일부로 제공됩니다. 선정된 고객에 대한 첫 번째 배송은 2023년 상반기에 시작될 예정입니다.
2022-08-25 04:02:28
작가: Vitalii Babkin